算能(Sophgo)是国内开发边缘计算处理器比较著名的公司
参加的一次竞赛,在使用其cv181x处理器部署深度学习模型时,因为开发环境cviruntime的官方文档不是很完整,所以在开发环境的搭建上折腾了一小段时间,随后便写下此文记录我个人的解决方案,以供新手查阅
安装WSL2
TIP提示
对于在Windows 11上已经安装了VMware Workstation Pro虚拟机以及搭建好了Linux开发环境的读者,可以跳过该章节
应用开发使用C++和cviruntime、OpenCV进行交叉编译,因此需要配置一个适合用于交叉编译的环境,我推荐习惯Windows的读者使用Windows Subsystem for Linux
先决条件
请在控制面板->程序->启用或关闭Windows功能里,启用Hyper-V、Virtual Machine Platform、Windows虚拟机监控程序平台、适用于Linux的Windows子系统,随后重启
安装Ubuntu WSL2
在Windows 11及更新的系统上,使用如下指令安装WSL2:
wsl --install -d Ubuntu安装完成后将会提示你创建用户以及输入用户登录密码
TIP提示
如果提示你升级WSL内核,请前往下载 Linux 内核更新包 - Microsoft Learn安装更新包并重新安装Ubuntu WSL
可选-将WSL移动到其它驱动器
WSL默认安装于C盘,如果你的C盘空间不够或者你有极强的文件约束习惯,可以使用以下操作将已安装的WSL移动到其它驱动器(请将我的目录地址以及用户名等修改为你的实际值):
备份原有的WSL操作系统:
wsl --export Ubuntu D:\Archives\ubuntu-wsl-initial.tar卸载已安装的WSL:
wsl --unregister Ubuntu将WSL安装到其它驱动器的新位置:
wsl --import Ubuntu D:\VirtualMachines\WSL\Ubuntu D:\Archives\ubuntu-wsl-initial.tar配置wsl默认用户:
wsl --manage Ubuntu --set-default-user maxwell(可选)配置wsl命令默认指代的实例,如果你同时安装了Docker Desktop,或者其他的WSL实例,请执行以下操作:
wsl --set-default Ubuntu安装Docker
Docker基于Linux命名空间实现资源隔离,因此可以很方便地在一个操作系统内部署多个不同的应用环境而互相不受影响
在Windows上安装Docker即在Windows上的Linux环境里安装Docker,读者可以选择在VMware Workstation Pro的Linux虚拟机里安装,也可以选择直接使用Docker Desktop
Docker Desktop使用WSL2提供的Linux环境,因此若想使用Docker Desktop需要预先确保Hyper-V以及WSL2已经被正确安装
随后转到Docker Desktop的官方网站下载并安装Docker Desktop
配置vscode
建议使用Microsoft VS Code作为你的编辑器,如果没有,请前往官网下载并安装
安装插件
对于C++开发建议使用clangd提供自动补全以及错误检查,为此你需要安装clangd插件。连接远程Linux系统需要使用SSH,因此你需要安装Remote Development捆绑插件
搭建基本Linux开发环境
使用以下指令连接上安装好的Ubuntu WSL:
wsl -d Ubuntu --cd ~
更换软件源
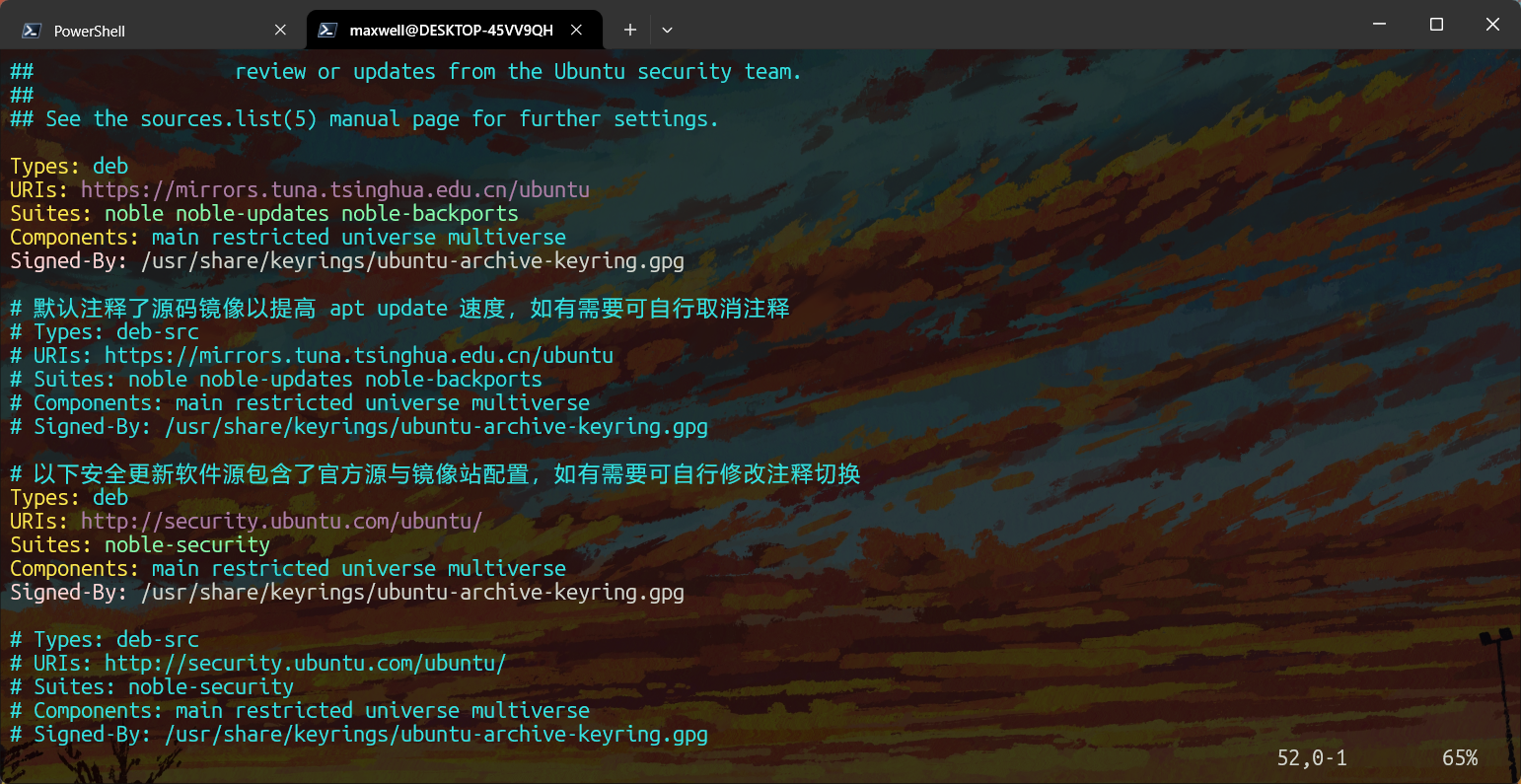
在Ubuntu上,更换APT软件源,如果你想使用清华大学开源软件镜像站,请转到他们的帮助页面查看如何更换软件源
补一张换源后的/etc/apt/sources.list.d/ubuntu.sources
安装基本软件
使用以下命令安装基本环境:
sudo apt install gcc g++ git cmake ninja-build python3 python3-pip clangd创建工具链目录
可以在用户主目录下创建一个sophgo目录用来存放TPU SDK、opencv-mobile以及riscv host-tools
cd ~
mkdir sophgo安装交叉编译工具链
算能cv181x具有两个架构的处理器:ARM和Risc-V
git clone 算能Risc-V工具链的编译后二进制仓库:
git clone https://github.com/sophgo/host-tools.gitWARNING注意
对于Risc-V,此处我们要使用的是musl libc而不是glibc,有关二者区别,请参考:
配置环境变量
我推荐使用一些Linux发行版例如openSUSE的做法,对于用户安装的应用,可以将其可执行文件链接到~/bin目录下
mkdir ~/bin
ln -s ~/sophgo/host-tools/gcc/riscv64-linux-musl-x86_64/bin/riscv64-unknown-linux-musl-* ~/bin通过以下命令可以检验软软链接是否被正确设置
ls -l ~/bin/riscv64-unknown-linux-musl-*如果正确地设置了软链接,那么会有下图所示的输出:
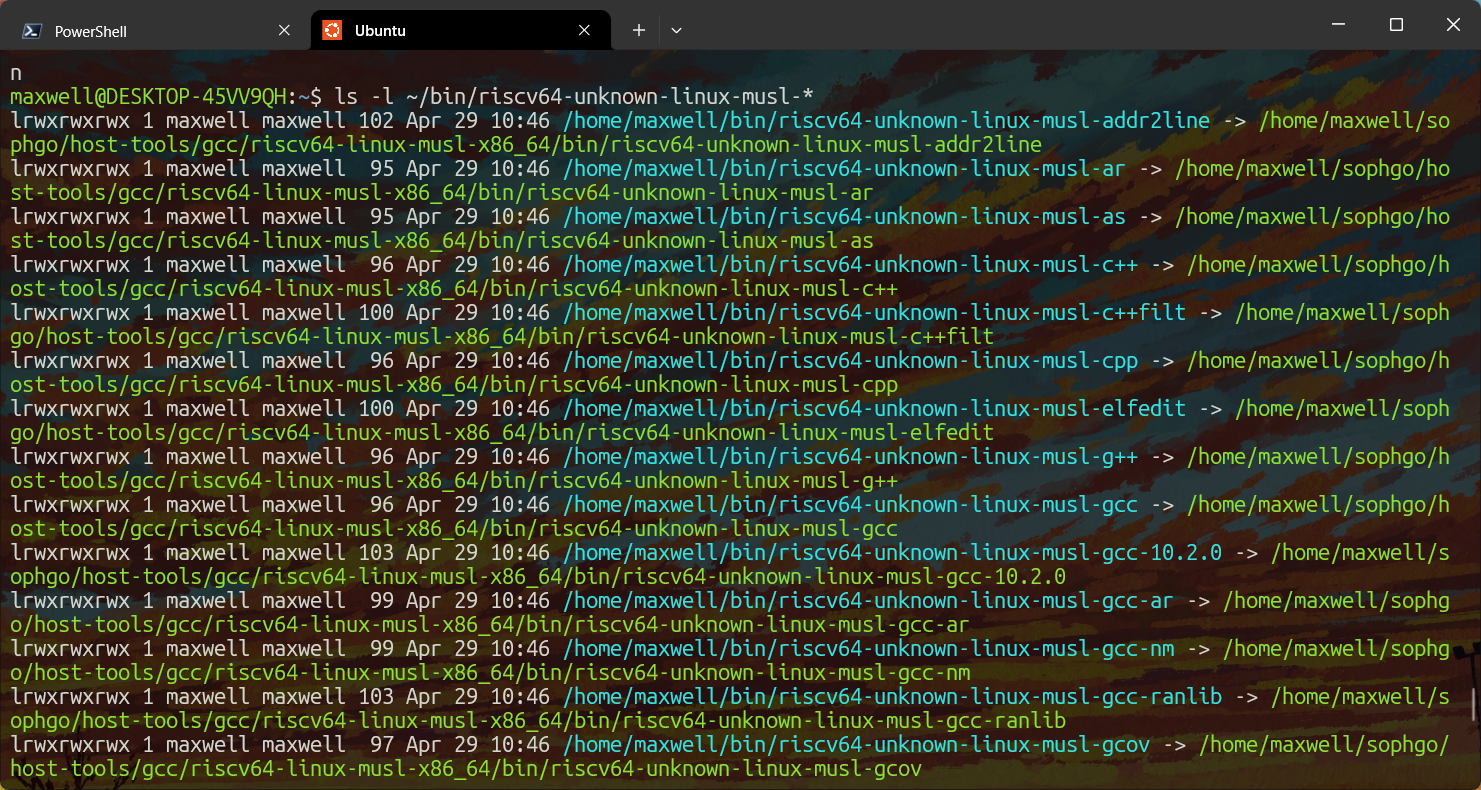
设置软链接后,执行任意~/bin/下的可执行文件就会实际上执行链接的目标文件
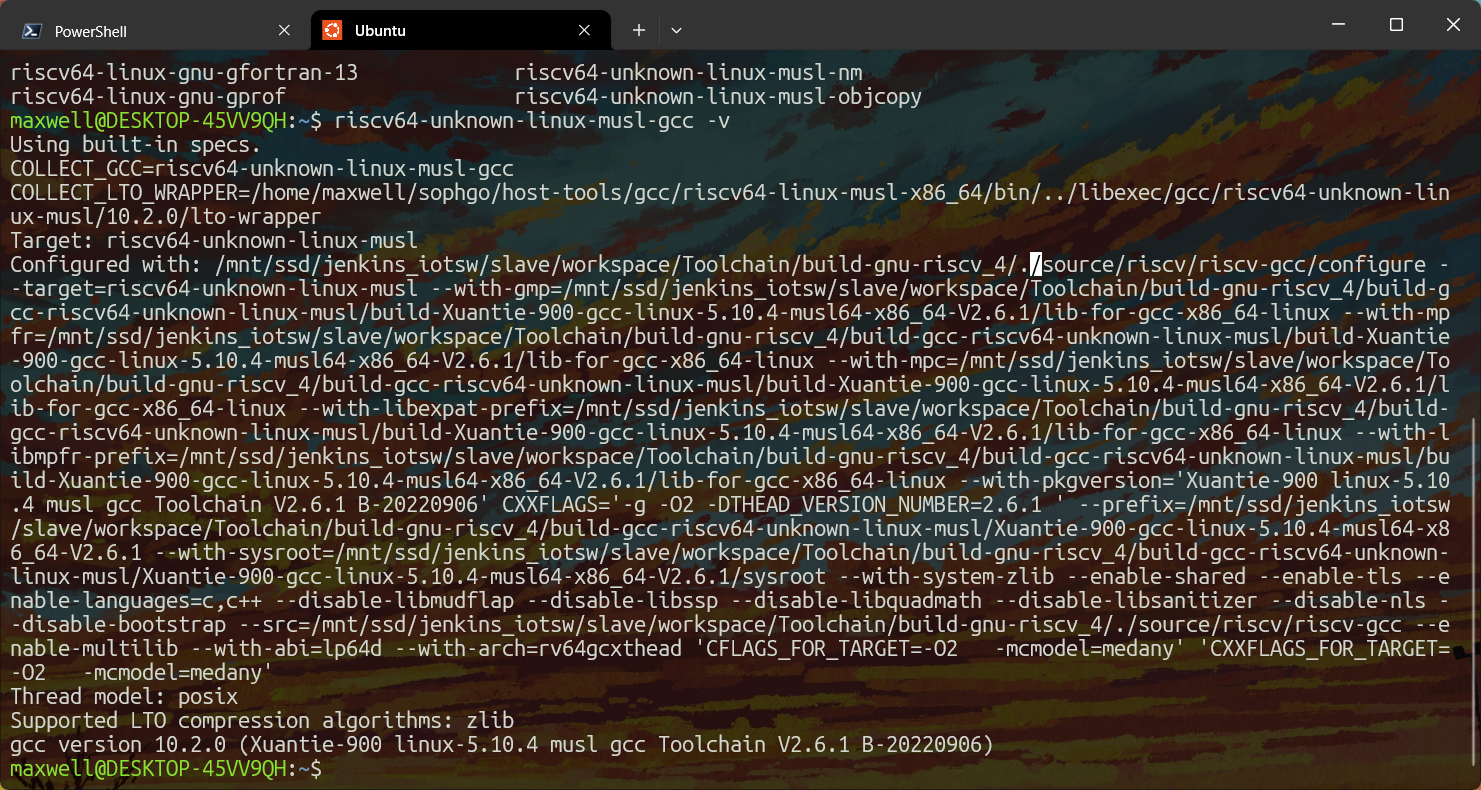
随后将~/bin目录添加进PATH环境变量即可,编辑~/.bashrc文件,在结尾处添加:
export PATH=~/bin/:$PATH关闭终端并重新打开,此时已经应用了新的环境变量,不出意外,此时执行riscv64-unknown-linux-musl-gcc -v会有输出:
搭建cviruntime环境
在算能设备上推理模型需要使用cviruntime调用其TPU,起初我使用Sophgo维护的cviruntime和cvikernel,结果因为该项目文档极少且错误较多屡次编译失败,最后找到了milkv-duo维护的sg200x-tpu-sdk,遂改为使用该SDK开发
克隆TPU-SDK仓库
切换到工具链目录git clone SDK仓库
git clone https://github.com/milkv-duo/tpu-sdk-sg200x.git tpu-sdk搭建模型开发环境
安装PyTorch、Jetbrains PyCharm,此处略过
搭建模型转换环境
在Docker Desktop里拉取sophgo/tpuc_dev:latest镜像
打开powershell使用下述命令启动容器:
docker run --name tpuc_dev -v /workspace -it sophgo/tpuc_dev:latestWARNING注意
milkv-duo的文档启动时具有一个参数--privileged,因为处于特权模式下的容器root用户具有与宿主机root用户相同的权限,我建议去掉该参数以保证安全性,关于利用Docker特权模式进行容器逃逸,请见记一次Docker下的Privileged特权模式容器逃逸
对于已经启动的容器,可以登录上去:
docker exec -it tpuc_dev /bin/bash在工作目录git clone 转换工具仓库
git clone https://github.com/milkv-duo/tpu-mlir.git搭建opencv-mobile开发环境
Milkv-duo为开发板适配了opencv-mobile,其与opencv相比更精简,且适配了一些外设,例如在使用CAM-GC2083时,如果使用opencv-mobile直接调用摄像头,那么此时就会更方便
安装方法很简单,在工具链目录下载并解压缩最新的发行版即可:
cd sophgo
wget https://github.com/nihui/opencv-mobile/releases/latest/download/opencv-mobile-4.11.0-milkv-duo.zip
unzip opencv-mobile-4.11.0-milkv-duo.zip
mv opencv-mobile-4.11.0-milkv-duo/ opencv-mobile
rm opencv-mobile-4.11.0-milkv-duo.zipTIP提示
如果提示找不到命令unzip,使用包管理器安装
测试环境
我们将在设备上部署Facebook Research的DinoV2特征提取器测试环境搭建是否正确
获取onnx模型
WARNING注意
这篇博客的之前某一个版本(2025.4.25 23:38,Commit:7f984a3)里我直接使用DinoV2进行ImageNet预测,这实际上是不对的,因为DinoV2只是一个特征提取器,不是一个分类器,如果读者想要对图像进行分类,应该在DinoV2骨干网络后增加一个分类头,而不是直接使用骨干网络进行分类
在读者目前看到的文章版本里,这个错误已经被修复
通过torch加载位于TorchHub的预训练模型,查看模型的详细信息并导出为onnx格式
import torch
import torchinfo
dinov2_vits14 = torch.hub.load('facebookresearch/dinov2', 'dinov2_vits14', pretrained=True)
torchinfo.summary(dinov2_vits14, (1, 3, 448, 448))==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
DinoVisionTransformer [1, 384] 526,848
├─PatchEmbed: 1-1 [1, 1024, 384] 226,176
├─ModuleList: 1-2 -- 21,302,784
├─LayerNorm: 1-3 [1, 1025, 384] 768
├─Identity: 1-4 [1, 384] --
==========================================================================================
Total params: 22,056,576
Trainable params: 22,056,576
Non-trainable params: 0
Total mult-adds (Units.MEGABYTES): 252.90
==========================================================================================
Input size (MB): 2.41
Forward/backward pass size (MB): 497.51
Params size (MB): 86.12
Estimated Total Size (MB): 586.03
==========================================================================================DANGER警告
如果仅仅将上述获得的模型导出为onnx格式,那么由于模型forward函数具有额外的除了张量以外的参数,会导致后续处理onnx模型时存在问题,因此我们需要对原有模型进行包装
import torch
import torch.nn as nn
import torch.nn.functional as F
class WrappedModel(nn.Module):
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, x):
return F.softmax(self.model(x), dim=1)
test_inputs = torch.randn(1, 3, 448, 448)
model = WrappedModel(dinov2_vits14)
torch.onnx.export(model, test_inputs, dynamo=False, f='dinov2_vits14.onnx', external_data=False)导出后onnx模型即为dinov2_vits14.onnx
TIP提示
如果提示torch缺失依赖库onnx、onnxruntime,安装即可
TIP提示
如果在安装onnx时,安装失败,出现子命令执行错误,以及cmake的运行错误提示,这可能是因为你的Python版本过高,onnx暂时没有为你的Python版本发布的二进制已编译的发行版,因此onnx在安装时会尝试从源码开始构建,那么此时如果你缺失了ProtoBuf等依赖库,就会编译错误
最为简单的解决方案是将Python降级一个版本,例如在我写这篇文章时,是2025年四月,我的环境使用的是Python 3.13.3,而onnx最高只有Python 3.12的已编译的发行版,此时就出现了这个错误,将Python降级为3.12.10即可解决该错误
TIP提示
如果你在安装onnx时,又出现了文件名或扩展名太长错误,这是因为Windows系统对于文件路径最长限制在260个字符,这可以在Windows 10/11上通过修改注册表键HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem\LongPathsEnabled,将键值设置为1解决,具体请参考最大路径长度限制-Microsoft文档
将onnx模型转换为cvimodel
进入转换工具的Docker环境,设置环境变量
source tpu-mlir/envsetup.sh
mkdir dinov2 && cd dinov2获取一部分图片用于生成校准数据,读者可以自行按照部署环境情况获取图片,也可以使用现有数据集,例如ImageNet-1k等
将onnx模型上传到Docker容器
docker cp dinov2_vits14.onnx tpuc_dev:/workspace/dinov2/dinov2_vits14.onnx利用model_transform.py将模型转换为mlir格式
model_transform.py \
--model_name dinov2_vits14 \
--model_def dinov2_vits14.onnx \
--input_shapes [[1,3,448,448]] \
--pixel_format "rgb" \
--mean 123.675,116.28,103.53 \
--scale 0.0171,0.0175,0.0174 \
--mlir dinov2_vits14.mlir使用run_calibration.py生成校准表
run_calibration.py dinov2_vits14.mlir \
--dataset imagenet \
--input_num 100 \
-o dinov2_vits14_calib_table将MLIR量化成INT8非对称cvimodel,并添加--fuse_preprocess选项将预处理阶段集成在模型内部:
model_deploy.py \
--mlir dinov2_vits14.mlir \
--asymmetric \
--calibration_table dinov2_vits14_calib_table \
--chip cv181x \
--fuse_preprocess \
--quantize INT8 \
--model dinov2_vits14.cvimodel完成转换后,使用model_tool查看cvimodel信息
model_tool编写cvimodel推理程序
在之前安装的Ubuntu WSL上创建项目文件夹,配置clangd插件,配置项目
mkdir guidance && cd guidance
mkdir build
mkdir .vscode && touch .vscode/settings.json
touch CMakeLists.txt
touch main.cpp
touch .clangd编辑vscode的工作区插件配置文件.vscode/settings.json:
{
"clangd.arguments": [
"--log=verbose",
"--background-index",
"--compile-commands-dir=build",
"-j=12",
"--clang-tidy",
"--all-scopes-completion",
"--header-insertion=never",
"--completion-style=detailed",
"--function-arg-placeholders",
"--pch-storage=memory",
"--fallback-style=LLVM",
"--suggest-missing-includes",
]
}编辑clangd配置文件.clangd以移除march和mcpu选项,防止因为clangd内置的引擎不支持这些选项造成错误误报
CompileFlags:
Remove:
- "-march=*"
- "-mcpu=*"编辑项目配置CMakeLists.txt
cmake_minimum_required(VERSION 3.25)
set(SOPHGO_TOOLCHAIN_PATH /home/maxwell/sophgo)
set(TPU_SDK_PATH ${SOPHGO_TOOLCHAIN_PATH}/tpu-sdk)
set(TOOLCHAIN riscv64-linux-musl-x86_64)
set(CMAKE_TOOLCHAIN_FILE ${TPU_SDK_PATH}/cmake/toolchain-${TOOLCHAIN}.cmake)
project(guidance CXX)
set(CMAKE_EXPORT_COMPILE_COMMANDS ON)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_C_STANDARD 11)
set(HOST_TOOLS_PATH ${SOPHGO_TOOLCHAIN_PATH}/host-tools)
set(CMAKE_SYSROOT ${HOST_TOOLS_PATH}/gcc/${TOOLCHAIN}/sysroot)
set(OPENCV_MOBILE_PATH ${SOPHGO_TOOLCHAIN_PATH}/opencv-mobile)
set(OpenCV_DIR ${OPENCV_MOBILE_PATH}/lib/cmake/opencv4)
find_package(OpenCV REQUIRED)
set(FLATBUFFERS_PATH ${TPU_SDK_PATH}/flatbuffers)
set(Flatbuffers_DIR ${FLATBUFFERS_PATH}/lib/cmake/flatbuffers)
find_package(Flatbuffers REQUIRED)
include_directories(${TPU_SDK_PATH}/include)
add_executable(guidance
main.cpp
)
link_libraries(${TPU_SDK_PATH}/lib)
file(GLOB CVI_LIBS ${TPU_SDK_PATH}/lib/libcvi*.so)
target_link_libraries(guidance
${OpenCV_LIBS}
${CVI_LIBS}
)编辑C++程序main.cpp
#include <cviruntime.h>
#include <opencv2/opencv.hpp>
void usage(char *program_name) {
printf("Usage: %s <model> <image>\n", program_name);
}
int main(int argc, char **argv) {
if (argc < 3) {
usage(argv[0]);
return EXIT_FAILURE;
}
const char *model_path = argv[1];
const char *image_path = argv[2];
// load model
CVI_MODEL_HANDLE model = nullptr;
int rc = CVI_NN_RegisterModel(model_path, &model);
if (rc != CVI_RC_SUCCESS) {
printf("CVI_NN_RegisterModel failed, err %d\n", rc);
return EXIT_FAILURE;
}
CVI_TENSOR *input_tensors, *output_tensors;
int32_t input_num, output_num;
CVI_NN_GetInputOutputTensors(model, &input_tensors, &input_num, &output_tensors, &output_num);
CVI_TENSOR *input = CVI_NN_GetTensorByName(CVI_NN_DEFAULT_TENSOR, input_tensors, input_num);
CVI_TENSOR *output = CVI_NN_GetTensorByName(CVI_NN_DEFAULT_TENSOR, output_tensors, output_num);
float input_qscale = CVI_NN_TensorQuantScale(input);
printf("input qscale: %f\n", input_qscale);
CVI_SHAPE input_shape = CVI_NN_TensorShape(input);
int32_t input_height = input_shape.dim[2];
int32_t input_width = input_shape.dim[3];
// Load input image
cv::Mat bgr_image = cv::imread(image_path);
if (!bgr_image.data) {
printf("Could not open image\n");
return EXIT_FAILURE;
}
cv::Mat image;
cv::resize(bgr_image, image, cv::Size(input_width, input_height));
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::Size size = cv::Size(input_width, input_height);
cv::Mat channels[3];
for (int i = 0; i < 3; i++) {
channels[i] = cv::Mat(input_width, input_height, CV_8SC1);
}
cv::split(image, channels);
for (int i = 0; i < 3; i++) {
channels[i].convertTo(channels[i], CV_8SC1, input_qscale, 0);
}
// input image to model
int8_t *input_ptr = (int8_t *)CVI_NN_TensorPtr(input);
int channel_size = input_height * input_width;
for (int i = 0; i < 3; i++) {
memcpy(input_ptr + i * channel_size, channels[i].data, channel_size);
}
// run inference
CVI_NN_Forward(model, input_tensors, input_num, output_tensors, output_num);
printf("CVI_NN_Forward succeeded.\n");
// Output results
float *features = (float *)CVI_NN_TensorPtr(output);
int count = CVI_NN_TensorCount(output);
printf("----------------\n");
printf("Image feature: ");
for (int i = 0; i < count; i++) {
printf("%.3f ", features[i]);
}
printf("\n");
printf("----------------\n");
// cleanup
CVI_NN_CleanupModel(model);
printf("CVI_NN_CleanupModel succeeded\n");
return 0;
}随后执行cmake配置,可以使用vscode自动配置也可以进入build目录手动配置
随后打开main.cpp可以看到clangd已经没有报错了,按住CTRL左键点击任何函数也能跳转到定义
切换到build目录,执行ninja或者使用cmake插件自动编译也可以
生成了guidance这个可执行文件,我们使用SCP将其以及cvimodel模型、测试图片传输到设备上
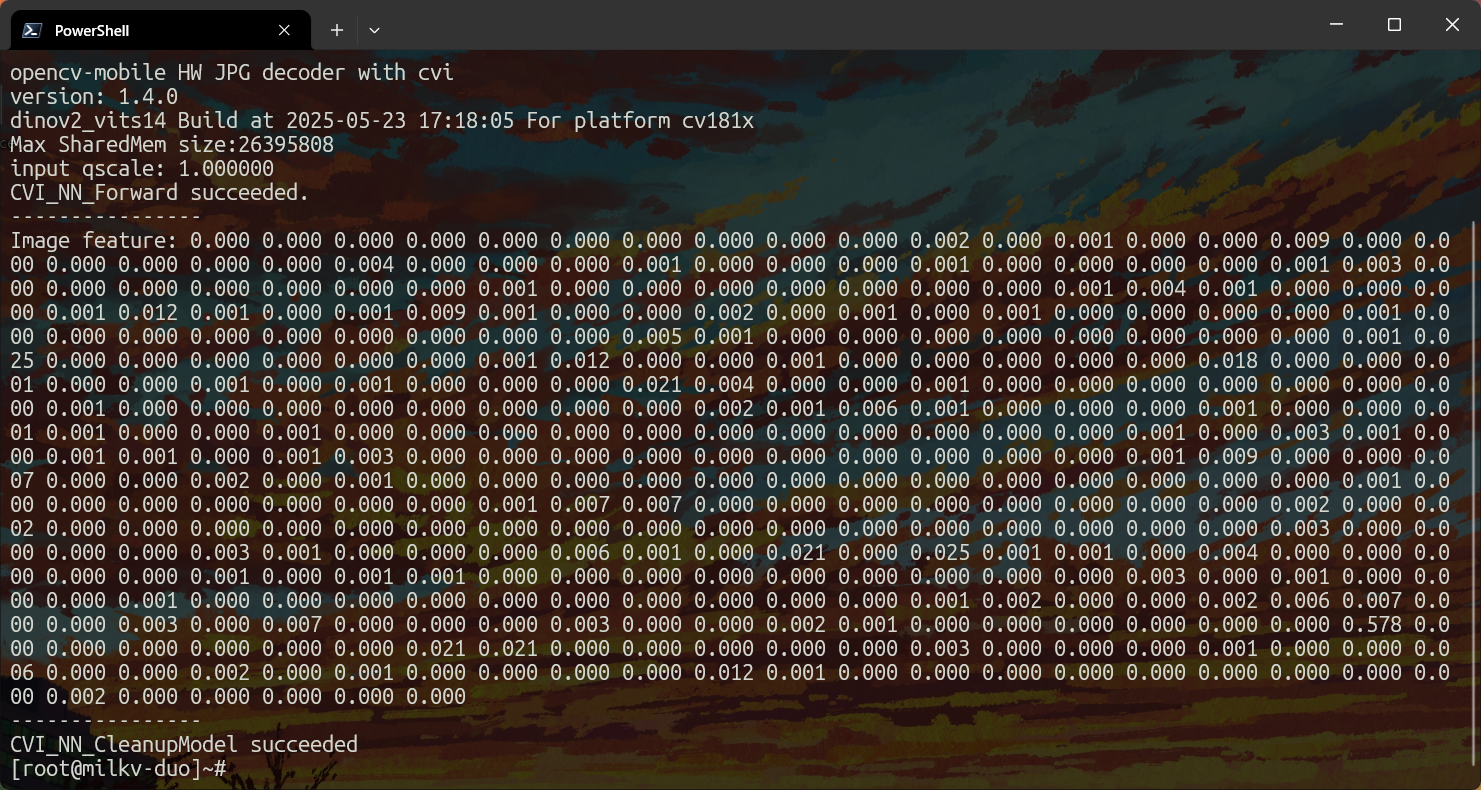
scp -O guidance imagenet/ILSVRC2012_val_00000178.JPEG dinov2_vits14.cvimodel root@192.168.42.1:/rootcviruntime的测试结果
使用SSH登录设备,给编译后的二进制文件授予可执行权限:
chmod +x guidance执行程序获得结果,注意此处结果只是一个384长度的向量,因为我们使用的模型是一个特征提取器而不是分类器,对于常见的分类模型,分类器会将特征提取器的输出经过一个全连接层,随后经过 后才会得到num_classes 个类的具体概率
./guidance dinov2_vits14.cvimodel ILSVRC2012_val_00000094.JPEG